| Major XML-aggregation Confusion [message #163901] |
Fri, 10 December 2010 00:27  |
 wittrs
wittrs

Messages: 134
Registered: August 2009
Karma: 0
|
Senior Member |
|
|
I'm dum cornfused.
For the life of me, I cannot figure out the sorcery of board's XML aggregator (or what not). I'm trying to do two things: (a) pick up a xml feed of a blog; and (b) syndicate a forum of my own board. Let's take each of these separately.
IMPORTING A FEED
1. I put the feed url in and created a "rule," just as one might for an email-list capture.
2. I've put in the php executable in the job-administration part of the board. It took the executable when I pressed "set." Next, I scheduled the job to run every minute.
3. I then pressed "run now," and it told me the job was scheduled to run in the background.
4. Nothing happened after several minutes. I pressed "log report" (or something) and it told me that the job either wasn't executed or nothing was captured.
5. I then reset the date on the rule. It told me that all the old messages would be captured. I repeated 3-4. Nothing happened. (It's as if I'm not concentrating enough when I flick the wand).
SYNDICATING MY OWN FEED
I pressed "syndicate this feed" on one of my threads. All it does is download secret xml sorcery code into a textfile. What do I do with it? I was under the impression that if I pressed "syndicate feed," that a new page would come up with the last 15 entries or so. How do I get my own board forum to display its feeds on a webpage?
Yours flunking wizardry.
|
|
|
|
|
|
|
|
| Re: Major XML-aggregation Confusion [message #163906 is a reply to message #163905] |
Fri, 10 December 2010 16:40  |
wittrs
Messages: 134
Registered: August 2009
Karma: 0
|
Senior Member |
|
|
Frank:
I have noticed one possible error. When I run the cron job myself, the feed becomes imported. HOWEVER, it only imports the body of the message, not the links. There does not appear to be a link to the original website (that I am importing) or links to which the body of text is referring.
Here is an example:
FEED: <?xml version="1.0" encoding="utf-8"?>
<feed xmlns="http://www.w3.org/2005/Atom" xmlns:dc="http://purl.org/dc/elements/1.1/" xmlns:thr="http://purl.org/syndication/thread/1.0">
<title>Legal Theory Blog</title>
<link rel="self" type="application/atom+xml" href="http://lsolum.typepad.com/legaltheory/atom.xml" />
<link rel="hub" href="http://hubbub.api.typepad.com/" />
<link rel="alternate" type="text/html" href="http://lsolum.typepad.com/legaltheory/" />
<id>tag:typepad.com,2003:weblog-104663</id>
<updated>2010-12-10T11:19:00-06:00</updated>
<subtitle>"All the theory that fits."Lawrence B. Solum</subtitle>
<generator uri="http://www.typepad.com/">TypePad</generator>
<entry>
<title>Snyder on the Judicial Genealogy of John Roberts</title>
<link rel="alternate" type="text/html" href="http://lsolum.typepad.com/legaltheory/2010/12/snyder-on-the-judicial-genealogy-of-john-roberts.html" />
<link rel="replies" type="text/html" href="http://lsolum.typepad.com/legaltheory/2010/12/snyder-on-the-judicial-genealogy-of-john-roberts.html" />
<id>tag:typepad.com,2003:post-6a00d8341bf68d53ef0147e08f21c6970b</id>
<published>2010-12-10T11:19:00-06:00</published>
<updated>2010-12-10T11:19:00-06:00</updated>
<summary>Brad Snyder (University of Wisconsin Law School) has posted The Judicial Genealogy (and Mythology) of John Roberts: Clerkships from Gray to Brandeis to Friendly to Roberts (Ohio State Law Journal, Vol. 71, No. 1149, 2010) on SSRN. Here is the...</summary>
<author>
<name>Lawrence Solum</name>
</author>
<content type="xhtml" xml:lang="en-US" xml:base="http://lsolum.typepad.com/legaltheory/">
<div xmlns="http://www.w3.org/1999/xhtml"><p>Brad Snyder (University of Wisconsin Law School) has posted <a href="http://papers.ssrn.com/sol3/papers.cfm?abstract_id=1722362">The Judicial Genealogy (and Mythology) of John Roberts: Clerkships from Gray to Brandeis to Friendly to Roberts</a> (Ohio State Law Journal, Vol. 71, No. 1149, 2010) on SSRN. Here is the abstract:</p>
<ul>
During his Supreme Court nomination hearings, John Roberts idealized and mythologized the first judge he clerked for, Second Circuit Judge Henry Friendly, as the sophisticated judge-as-umpire. Thus far on the Court,Roberts has found it difficult to live up to his Friendly ideal, particularly in several high-profile cases. This Article addresses the influence of Friendly on Roberts and judges on law clerks by examining the roots of Roberts's distinguished yet unrecognized lineage of former clerks: Louis Brandeis's clerkship with Horace Gray, Friendly's clerkship with Brandeis, and Roberts's clerkships with Friendly and Rehnquist. Labeling this lineage a judicial genealogy, this Article reorients clerkship scholarship away from clerks' influences on judges to judges' influences on clerks. It also shows how Brandeis, Friendly, and Roberts were influenced by their clerkship experiences and how they idealized their judges. By laying the clerkship experiences and career paths of Brandeis, Friendly, and Roberts side-by-side in detailed primary source accounts, this Article argues that judicial influence on clerks is more professional than ideological and that the idealization of judges and emergence of clerkships as must-have credentials contribute to a culture of judicial supremacy.
</ul></div>
</content>
Here is what I get:
Quote:Brad Snyder (University of Wisconsin Law School) has posted The Judicial Genealogy (and Mythology) of John Roberts: Clerkships from Gray to Brandeis to Friendly to Roberts (Ohio State Law Journal, Vol. 71, No. 1149, 2010) on SSRN. Here is the abstract: During his Supreme Court nomination hearings, John Roberts idealized and mythologized the first judge he clerked for, Second Circuit Judge Henry Friendly, as the sophisticated judge-as-umpire. Thus far on the Court,Roberts has found it difficult to live up to his Friendly ideal, particularly in several high-profile cases. This Article addresses the influence of Friendly on Roberts and judges on law clerks by examining the roots of Roberts's distinguished yet unrecognized lineage of former clerks: Louis Brandeis's clerkship with Horace Gray, Friendly's clerkship with Brandeis, and Roberts's clerkships with Friendly and Rehnquist. Labeling this lineage a judicial genealogy, this Article reorients clerkship scholarship away from clerks' influences on judges to judges' influences on clerks. It also shows how Brandeis, Friendly, and Roberts were influenced by their clerkship experiences and how they idealized their judges. By laying the clerkship experiences and career paths of Brandeis, Friendly, and Roberts side-by-side in detailed primary source accounts, this Article argues that judicial influence on clerks is more professional than ideological and that the idealization of judges and emergence of clerkships as must-have credentials contribute to a culture of judicial supremacy.
|
|
|
|
|
|
|
|
| Re: Major XML-aggregation Confusion [message #163914 is a reply to message #163901] |
Sat, 11 December 2010 14:52 |
wittrs
Messages: 134
Registered: August 2009
Karma: 0
|
Senior Member |
|
|
... alright, I get the idea that <a href, etc.> is escaped, and that < (etc.) is not. But are you saying that there is no way to make it so that, if someone has <a href> in their feed, that it can be imported as < (etc.)? Wouldn't a regex sort of thing accomplish that? I notice there isn't a body mangling option in the page that creates the xml rule -- so, if someone were to attempt such a thing, it would go directly in the xml-aggregation php file? (Not sure I'm handy enough to try that, but in the future, who knows?).
Thanks as always! (This XML thing looks nifty; I can import all of my blogs into my forum).
|
|
|
|
|
|
| Re: Major XML-aggregation Confusion [message #163917 is a reply to message #163915] |
Sat, 11 December 2010 18:32 |
wittrs
Messages: 134
Registered: August 2009
Karma: 0
|
Senior Member |
|
|
Hi again Frank. Is there any way in the future to have the linked-title of each entry captured? Take a look at this, which is a capture of the defective feed we have been talking about:
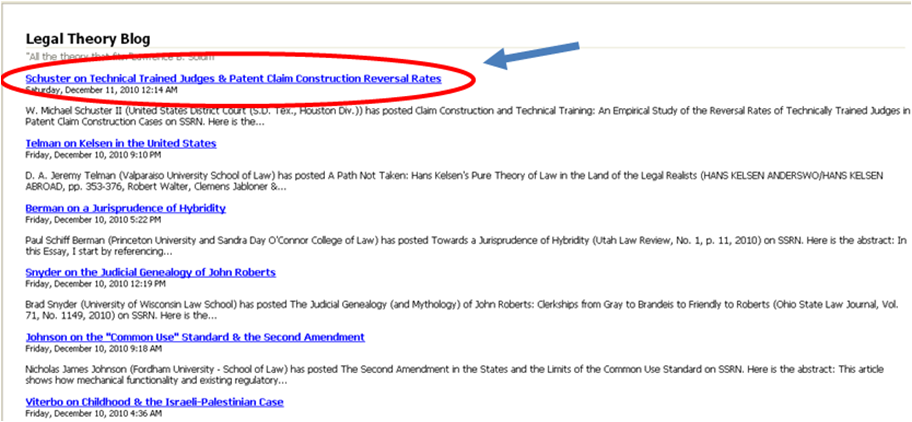
Note two things: (1) it has the titles of each entry and a link; and (2) the defective links from the body of the feed are escaped. I'm trying to find a way so that if I capture a feed, the author's specific webpage gets appropriately credited. I do realize that I could place a signature below each item that takes you to the author's main page. But I was hoping in the future to take you to the exact page that the feed entry is quoting.
Sorry to be a pain in the rear. Just passing along a suggestion for the future perhaps. Appreciate your patience.
[Updated on: Sat, 11 December 2010 18:34] Report message to a moderator |
|
|
|
| Re: Major XML-aggregation Confusion [message #163918 is a reply to message #163917] |
Sat, 11 December 2010 19:23 |
Ernesto

Messages: 413
Registered: August 2005
Karma: 0
|
Senior Member |
|
|
I do not understand what you mean wittrs.
This is the content of a typical RSS feed:
<title>This is the title of the post/newsitem</title>
<link>This is a link to the single post/newsitem</link>
<description>This is description</description>
<pubDate>2010-12-11T22:12:00+00:00</pubDate>
<author>Author(at)mail(dot)com</author>
This is also what the forums RSS parser grabs - title, url, content, date and author. This is what the feed contains, this is all you can add, this is what the forum will grab.
The linked title is always captured, the title is set as the post title and the URL is inserted in the post.
It does take you to exactly the page the feed is "quoting".
The feed you screenshotted (http://lsolum.typepad.com/legaltheory/index.rdf) is a valid feed.
Ginnunga Gaming
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| Re: Major XML-aggregation Confusion [message #163942 is a reply to message #163901] |
Tue, 14 December 2010 03:45 |
wittrs
Messages: 134
Registered: August 2009
Karma: 0
|
Senior Member |
|
|
.. just a quick update. I had to turn this feed off. It kept downloading the same single message.
Imagine a feed with 12 messages, X(1) through X(12). Instead of downloading 12 messages, my board only received X(1). And each time the cron job ran, it received X(1) again. And again.
What appears to have happened is that the iteration failed (is that the right word)? It wouldn't go though the process of extracting all of them. And it seemed to exit the program early, because the date on the aggregation rule remained 1970.
Any help you can think of would be great. I'm going to look into it myself tomorrow.
|
|
|
|





") ]
]